
Using AI for Data Modeling in dbt
From raw data to a semantic layer with Cursor and dbt’s Fusion engine

This is part one of a three-part series on using AI in data engineering. In Part 1, we look at how you can use AI in data modelling. In Part 2, we test and monitor the data using AI, and in Part 3, we show you how to perform self-serve analytics on a semantic layer.
In this post, we’ll explore how you can use AI in data modeling, from extracting information from raw data to structuring your project, creating transformations, and building a final mart and semantic layer in dbt.
We’ll be using Snowflake, dbt core (with the Fusion engine), Cursor for coding, supplemented by ChatGPT for prompting, and Omni as the BI layer.

Let’s get started!
Loading the data
We’ll use publicly available data from “Finans Danmark” about housing in Denmark since 1992. If you’re curious, you can explore the data on finansdanmark.dk (in Danish). We’re manually extracting data as CSV across these datasets
Houses on Market — Count of listed or withdrawn houses by type
Loan Offers — Number of loan offers by region, type, and purpose
Sales Times — Days to sell by region and housing type, incl. listing duration
Sales Prices by Postcode — Sale prices by postcode, type, and price metric
Sales Prices by City — Average prices per m² by city and property type
For simplicity, we’ll upload these into Snowflake as raw data sets.
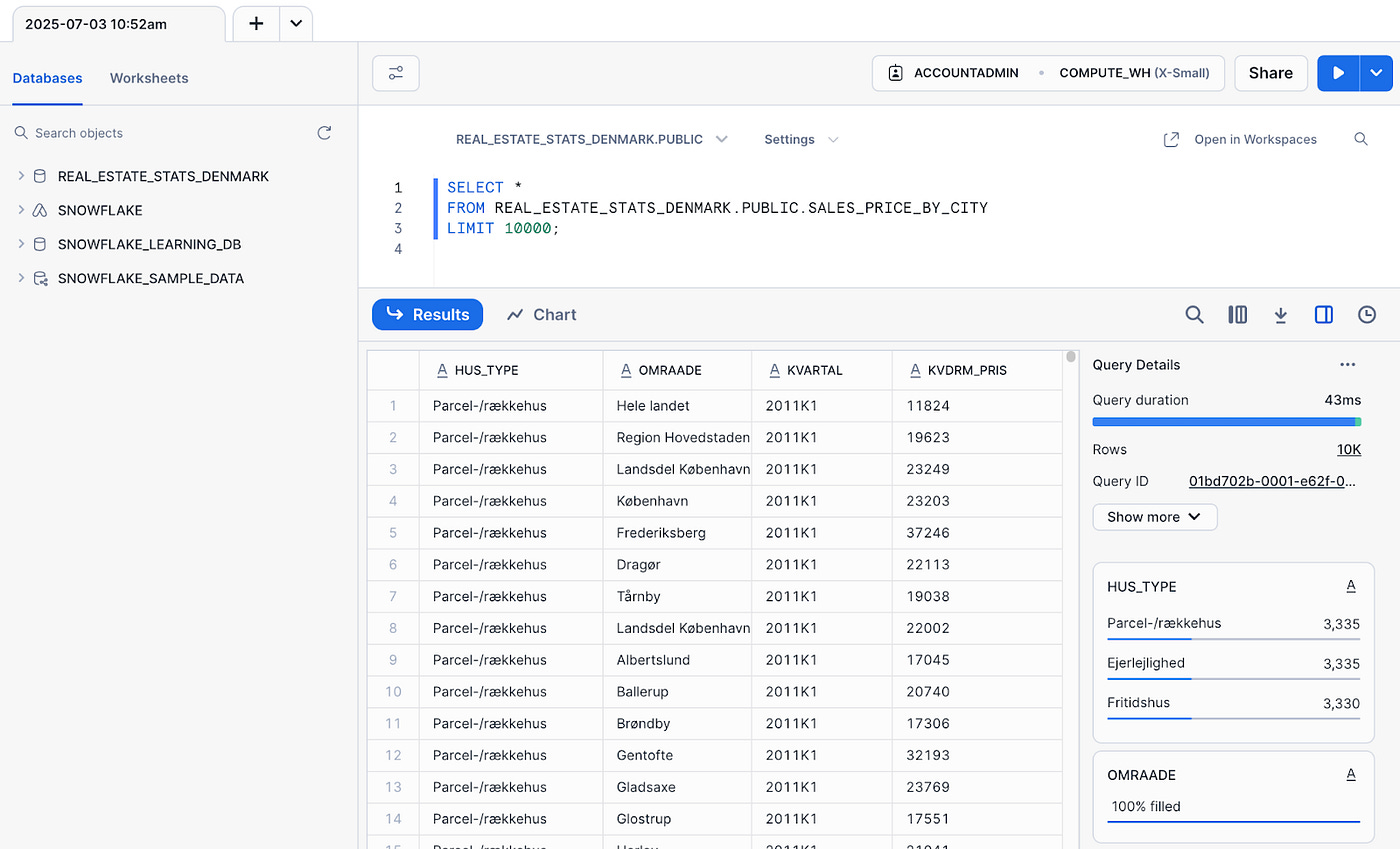
Next up is loading this data into dbt.
Structuring our dbt project
It’s a good idea to think about the project structure from the get-go, both what it looks like from the start and what it would look like if you add more models, so you can avoid having to refactor data unnecessarily.
We prompt Cursor to give us a model structure based on a link we provide:
✨Prompt: "I may be adding more models, so I want a scalable setup from the beginning
- Follow the guidelines here: https://docs.getdbt.com/best-practices/how-we-structure/1-guide-overview
- Create different folders based on the categories you can infer from the table names (e.g., sales, loans, market timing)
- Create a sources.yml file from the list of tables in Snowflake I provided"We now get back a neatly structured folder structure and a sources.yml file pointing to the right sources.
models/
├── sources.yml
├── staging/
│ ├── market_timing/
│ ├── loans/
│ └── house_sales/
├── intermediate/
└── marts/Modelling our data in Cursor with the dbt extension
We’ll be using dbt’s VSCode extension and the newly released Fusion engine in Cursor to speed up some core workflows. Cursor helps us directly translate text into components with all of the context of the codebase in mind. The dbt extension helps us speed up core workflows, such as the ability to see syntax errors in real-time in the editor without needing to run dbt, and see the output of query results.
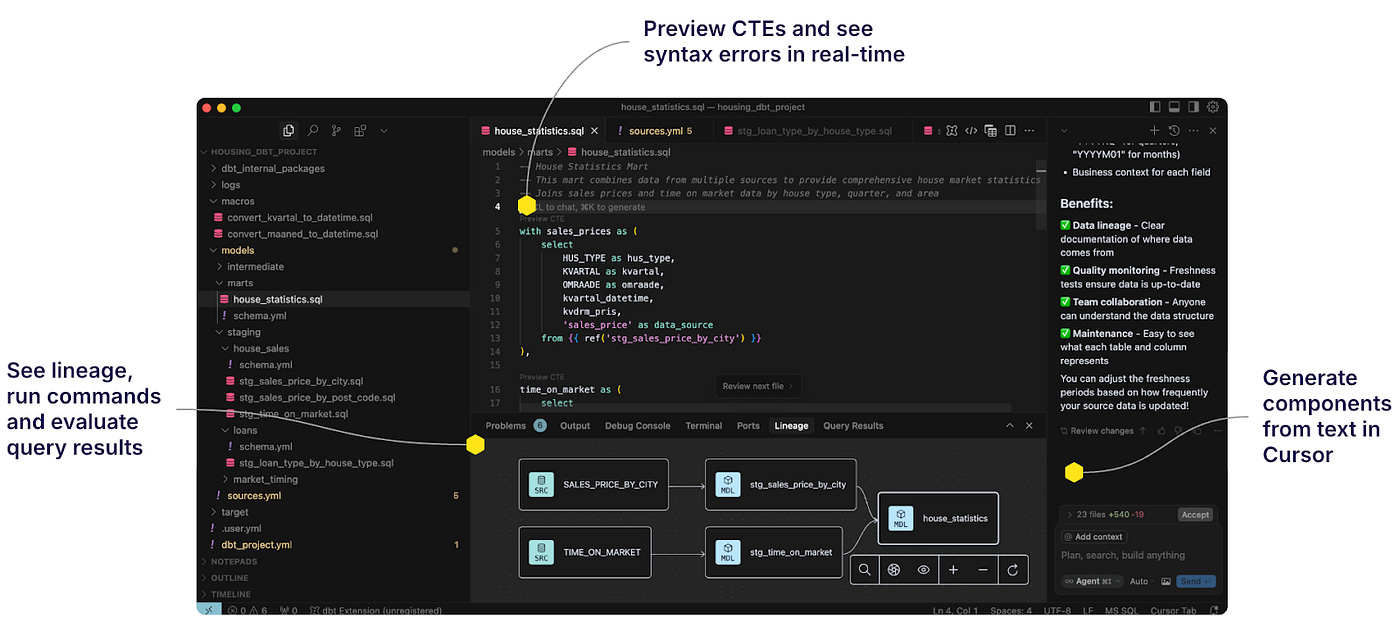
The first step of data modelling is to take the raw data and clean it up in staging tables, by making date formats consistent, and applying high-level logic. We should, of course, use our specific knowledge of the dataset to do this, but Cursor can be very useful here as well.
✨Prompt: “I have a few real estate datasets from Snowflake. Here's a sample of 10,000 rows from each table. Can you analyze them and tell me what I should watch out for when doing data modeling? For example, numeric fields stored as strings, strange date formats, inconsistent values, or anything else that might cause issues”Using the prompt above, we extract sample data from all sources and feed it to the AI, asking it for any inconsistencies or patterns to clean up. Below is the response, clearly highlighting some issues around metrics being stored as strings, and the KVARTEL (quarter) column not being stored as a proper datetime format.
The DAGE column, which represents days on market, is stored as a string — e.g., “93”. While this works for display, it breaks filtering, numeric comparisons, and averages unless explicitly cast to INT or FLOAT. Before modeling or aggregating, it’s best to apply a cast: CAST(DAGE AS INT).
The KVARTAL field stores quarter values as strings like “2021K3”. While readable, these don’t sort properly — “2021K10” comes before “2021K2”, which breaks time-series grouping. A better approach is to parse the quarter string into a date using something like TO_DATE(KVARTAL || ‘-01’, ‘YYYY\”K\”Q-DD’), or extract year and quarter components into separate fields.
Taking this into account, we specify a simple modelling strategy for our staging layer and provide it to Cursor.
✨Prompt: "For all files in the staging folder except for stg_houses_on_market, I want you to add the following transformations
- KVARTAL should be converted to a datetime
- It should be done using a macro, so it's scalable, and placed in the macros folder
- Ensure that the metric for each table is converted to the appropriate numeric format
- If you spot any metric that's inconsistent with a numeric format, replace it with null
- Use any information about the raw data from the sample files I shared"Cursor now creates a set of neatly formatted staging tables, taking the logical considerations into account, neatly accounting for specific cases of the data (e.g., ‘…’ used instead of null values in the raw data)

Modelling marts for business logic
We usually don’t want to use data directly from the staging tables for end-user applications such as dashboarding. In our case, we want a set of well-defined data models we can expose in a BI tool, and a semantic layer for natural language questioning.
A good strategy here is to describe what the outcome or ‘job to be done (JTBD)’ is for the data model. For example, if there are specific questions you’d like to be able to answer, the model can automatically infer if certain tables should be joined.
✨Prompt: "Build a data mart called house_statistics to analyze housing trends by correlating house prices, loan types, and interest rates across house types (hus_type), regions (omraade), and quarters (kvartal). It combines data from three staging tables: stg_sales_price_by_city, stg_time_on_market, and stg_loan_type_by_house_type, using a left join on the shared dimensions to ensure no rows are dropped."Before you start building models, I recommend asking:
✨Prompt: "Any questions to clarify before we start"Asking the last questions gives you some good sparring for ideas. In my example, some of then questions return are: “Do you want me to create calculated fields that show correlations between the different metrics (e.g., price-to-time ratios, loan activity indicators)?” and “Missing data handling: How should we handle cases where some staging models don’t have data for certain combinations (e.g., loan data might not exist for all house type/region/quarter combinations)?” These are all questions you want to make a decision on before building the models.
That’s a good start! A few back-and-forths like this, and you start having some marts that represent the logic we want in our BI tool.
Building our semantic layer
In part 3 of this series, we’ll be looking into using LLMs to explore the data in our dbt project, with the ability to ask questions such as “what are the most expensive postcodes?” and “which cities have seen the largest increase in house prices?”.
For this, the semantic layer is a great interface as it limits the context the LLM will use to only vetted metrics. Jason Ganz from dbt wrote a great article on how to use the dbt MCP server alongside Claude.
Asking Cursor to make us a metrics.yml file with key metrics from the final mart is easy. There’s a bit of work in manually going through this afterwards and making sure that the metrics there make sense
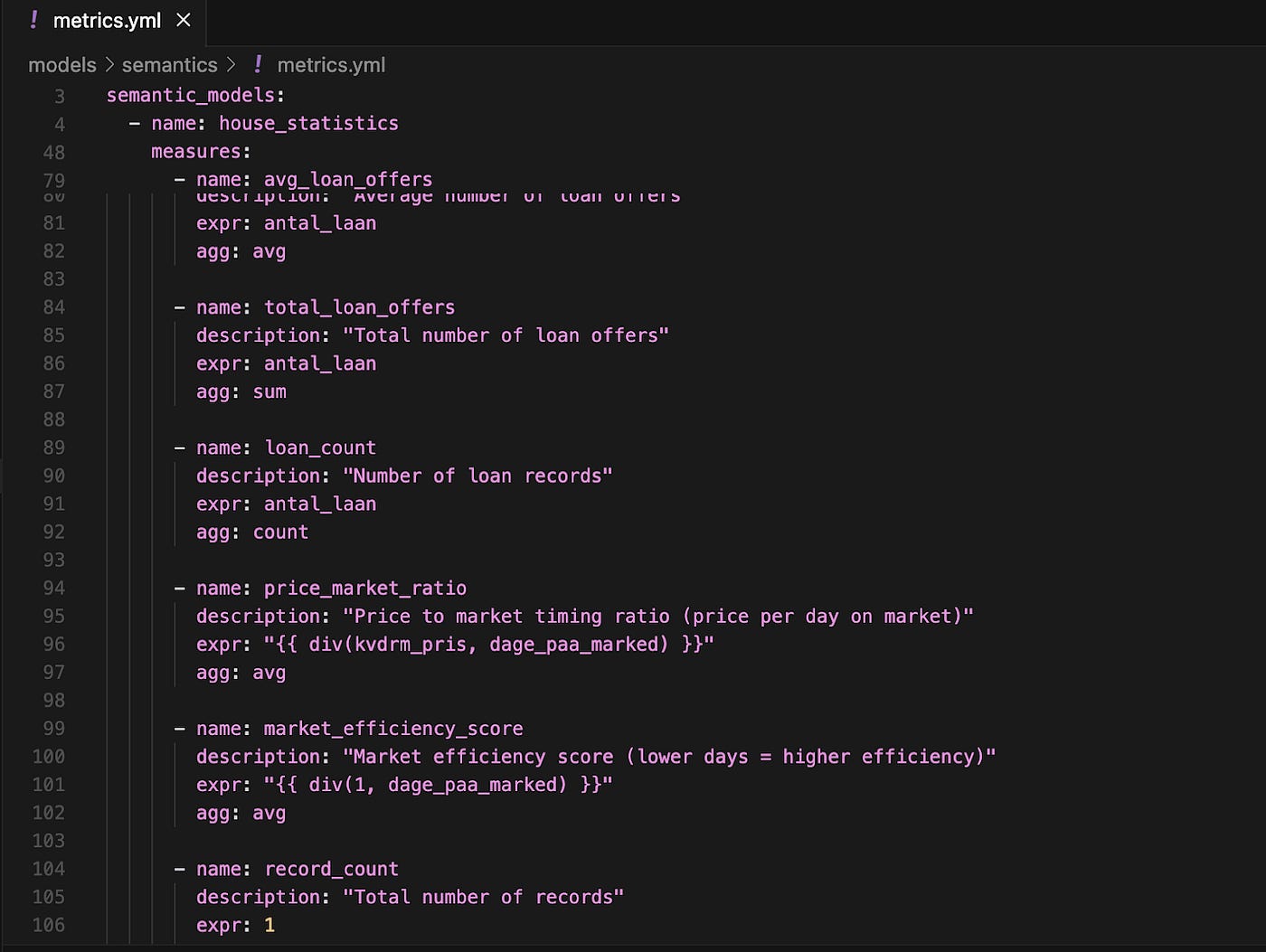
Some metrics are the expected ones. Others, such as market_efficiency_store, are made up. While I ended up discarding most of the made-up metrics, a few of them were interesting, and I kept them around. This is a good case for sometimes letting the AI run a bit wild to help you generate new ideas.
Adding descriptions to our data models
Documenting and describing your data is often not the most fun task. But with AI, this becomes significantly easier.
✨Prompt: "Given the sample data I provided, write a one-line description of what the table contains, followed by a short description for each column. Include the data type if it's clear, and use specific examples from the data in the descriptions where helpful. Use specific examples for each column of what data is contained based on the most common values"With this prompt, the agent looks at the sample data provided and adds reasonable descriptions with clear examples based on the most commonly occurring values. It’s of course, no substitute for manually adding context, but a good start!

We now have a ready-to-explore semantic layer with well-defined and clean metrics. That’s the wrap of part 1. All this was done in just a few hours. By my estimation, AI has taken away at least 80% of the work here.
Here’s a recap of what we did
Loaded data into Snowflake
Created a dbt project structure with relevant sources
Autogenerated staging models based on best practices
Used sample data to clean the data in the staging layer
Focused on our outcomes to create a clean data mart
Set up a semantic layer for querying in an LLM in part 3
Automatically documented the data using real examples
In the next post in this series, we’ll look into how you can apply some of the same techniques to deploy a testing and monitoring strategy