
Data team structure: embedded or centralised?
Embedded data teams are closer to business problems but ownership of what to do when data goes wrong is complicated

It seems like everyone is working out how to structure data teams in their own ways. When I talk to data leaders I frequently hear mentions of the following topics
Should my data team operate centralised or embedded?
What technical implications does this have?
What’s the right data team constellation?
Getting this right (if there’s such a thing as right here) is no small deal as a lot of things will fall in or out of place depending on how you set your team up.
Should my data team operate centralised or embedded?
Some teams naturally tie themselves to being centralised. Data engineers for example benefit from working on shared objectives such as improving data pipelines or tooling. Analysts with domain expertise in credit modelling may tie themselves better to being fully embedded and working as part of a business function.
But for data analysts, data scientists and analytics engineers the answer is less clear.

Here are some simple guidelines I have seen work in the past.
Find your team stretched thin across too many stakeholders, bogged down by ad-hoc requests and constantly having to take shortcuts when it comes to data quality? Then perhaps it is time to work more centralised.
Find yourself with a centralised growing data team but having a hard time keeping context on all the business areas you support with stakeholders complaining that data people are not close enough to business problems? Then maybe it’s time to decentralise.
In reality you’ll often have to alternate between the two models and what worked well six month ago may no longer be the right model if the team or priorities have changed.
Data team structure is also a technical challenge
Bryan Offutt wrote a great article “The Next Big Challenge for Data is Organizational”. But how you structure data teams quickly becomes a technical challenge as well.
In the old world where data teams largely operated as a central, service-like function you could do stand-ups as one team, prioritise what to work on and keep track of everything in one backlog.
In the new world of embedded data teams the reality is very different.
A not too uncommon scenario starts with an engineer making a change in a backend microservices that causes a metric to be wrong downstream in a Looker dashboard. For the engineer this is a small fix and can be reverted in 5 minutes. For the data team this could mean days of work to uncover.

What seems like a simple answer quickly turns into dozens of Slack threads. Questions such as “did anyone make a change to the users data model?” or “who owns the payments_merchant table after Jamie left?” are popping up left and right. And there’s a good reason for this. To get to an answer you often have to traverse multiple domains, work through data model dependencies created by people who have since left the company and navigate spreadsheets with outdated mappings that power important business logic.
In scale-ups with large data teams embedded across dozens of business and product teams, uncovering what happened when there is a data issue is like searching for a needle in a haystack
Unfortunately this means that upwards 30% of time spent by data teams are on this type of work instead of uncovering new insights or working on moving their goals forward.
What’s the right data team constellation
Centralised or not, what’s the right constellation of a data team? Larger data teams often consist of some combination of data engineers, analytics engineers, data analysts, data scientists and machine learning engineers. Smaller data teams sometimes make do with three of the five roles (although not everyone agree that the data science title should exist).

What’s the right ratio of each
I’ve previously written about the importance of balancing the mix between people working on making life easier for others (i.e. data engineers) and those working on driving a KPI (i.e. data scientist).
As a naive rule of thumb, if a data engineer could make a change that makes dbt 10% faster for 100 dbt users but can’t prioritise this you probably don’t have enough data engineers. If data scientists are bogged down by ad-hoc requests and leaving high potential ROI opportunities on the table, you should probably hire more.
One role however sits somewhere in the middle between data coming into the data warehouse and insights; the analytics engineer.
I found it difficult to come up with a rule of thumb for what the right size of an analytics engineering team is so I had a look at LinkedIn to understand how a few companies have structured their data teams.
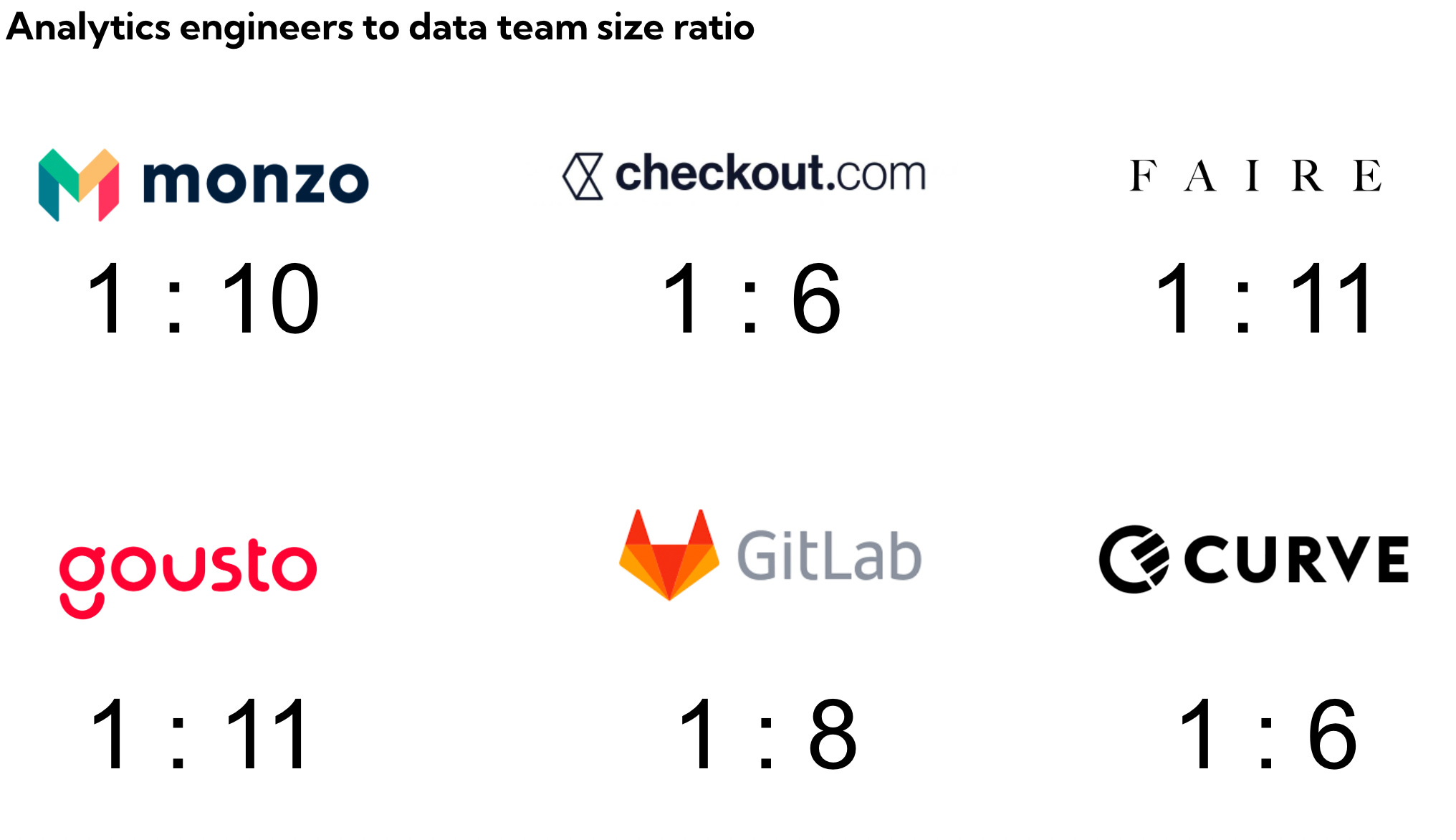
As an aside, in a previous analysis I found that the median data to engineers ratio for top European tech startups is 1:4.
If you have any tips on how to structure data teams, what the right ratio of analytics engineers is or how to manage data issues that span many business domains, I’d love to hear from you.
Possibly a dumb question but of those roles who is then responsible for producing standardised reports and dashboards? Does that fall to analytics engineers, or data analysts, or a bit of everyone?
Our "# of analytics engineers : total data team size" ratio is: 1:1
:P
We'll be moving that ratio in the future but it'll likely stay at something like 1:2 forever, or at least for a long time. There are very interesting implications of this ratio, I 100% agree with you. You can read in our ratio our level of belief in self-service analytics, enablement of this, and overall pipeline quality. Also the belief that analytics engineers can flex into the downstream analytics space.